日志模块的解析及应用
Context
日志的重要性不言而喻:定位单个问题、收集数据、汇总分析。
那么在当前的服务器越来越复杂的情况下,不清楚日志的记录时机、记录状态、所在位置,就会手足无措,不知道如何下手。
工欲善其事,必先利其器,首先对日志分个类吧。
日志的分类
| 类别 | 来源举例 | 收集分析工具 | 说明 |
|---|---|---|---|
| 访问日志 | nginx、apache | goaccess、 visitors | 用户请求来源、IP、浏览器、最常用页面、出错页面 |
| 业务日志 | python的logging模块 | sentry、crashlog | 业务的信息等出错信息 |
| 行为日志 | 业务自定义 | 自定义 | 分析用户的行为数据、如点击热点等 |
| 出错日志 | 代码级错误(crash) | 无 | 如编译出错、导包问题等(500错误) |
我们来分而治之。先介绍访问日志。
访问日志
用户发起HTTP请求,由服务器记录的当前访问的HTTP头信息,包括IP、请求URL、返回状态、来源、浏览器型号等。
主要由http服务器提供,时下流行的就有nginx, apache包括gunicorn等。
由于这种类型的日志格式较固定,因此对应的分析器也就非常容易了,常见的就是goaccess,visitors。
可以针对请求IP、请求URL、返回状态等进行自动分类整理,有利于对访客、访问量进行分析。
接下来就介绍业务日志。
业务日志
提到业务日志,这个就跟语言强相关了,不同的语言,处理框架不一样,因此可能在不同的语言里,也有不同的表现形式。
这里重点介绍python中的logging模块。
照例先介绍一下概念。
Logger(记录者)
用户区分不同的日志、相当于对于日志类的实例化对象。调用是使用logging.getLogger(logger_name),当logger_name不指定时,默认为root。
Handler(处理器)
用于处理日志的,一个日志输入可以有多个处理器,python中的常见处理器有这些处理器。
StreamHandler,流处理器,将日志输出到stdout或者stderr。
FileHandler,文件处理器,将日志输出到文件中,文件将一直增长下去。
RotatingFileHandler,自分割的文件处理器,会按文件大小,自动对文件切割。
TimedRotatingFileHandler,时间分割的文件处理器,会按时间来切割。
SocketHandler,套接字处理器,将数据发送到其它进程。
SMTPHandler,邮件处理器,发送邮件。
Formatter(格式)
定义的格式,一个处理器对应一个格式。
以下是它们的关系图
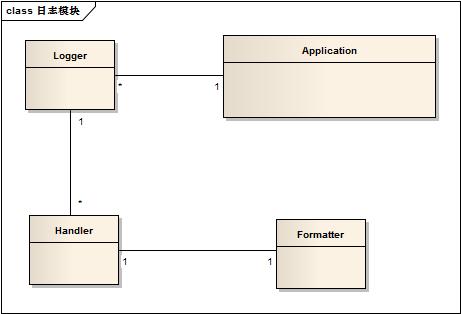
可以看到,应用程序可以对应多个logger,而一个logger可以对应多个handler。
知道了他们的关系后,是能组合出非常多的功能的,比如下面的这些场景:
- 严重级别的错误,直接发送邮件知会
- 普通错误信息,汇总到一台服务器,进行收集整理,并可以与bug系统结合、用于跟踪解决。
行为日志
由于日志相对数据库来说,开销较小,数量也有较大上限,因此可以作为记录行为数据的最好载体。
比如用户在某一时间,做了什么操作,这个可以通过日志非常方便的管理与整理。
然后每天由定时任务自动对日志文件分析处理,再将分析之后的数据入库。
这个并没有现成的工具,需要结合业务自己来完成。
最后就是错误日志。
出错日志
其实像一些服务器500错误,这个是比较难定位的,很可能python编译都不通过(如缩进问题)。
甚至在logging模块加载前就出错了,这时日志里自然记录不到任何东西。
但是一般出错时,堆栈信息也会被扔到stderr中去,可以用另外的工具收集。